Nvidia A100 - az elsõ Ampere grafikus processzor
Bár sokan várták, a frissen bejelentett fejlesztés még nem a lakossági RTX modellekkel konkurál![]()
A járvány miatt elmaradt GTC konferencia, és a még márciusról is tovább csúsztatott online bemutató miatti hosszas várakozásnak vége, megtörtént az elsõ nagy bejelentés. Bár sokan reménykedtünk, hogy az otthoni felhasználókra is gondolnak majd, Jensen Huang vezérigazgató ezalkalommal csak az új Ampere technológia újdonságaival készült, melyeket az eddigi legméretesebb ipari GPU-szörnyeteggel együtt mutatott be.
A bejelentés középpontjában természetesen az új Ampere mikroarchitektúra állt, mely elsõsorban a 2017 végén bevezetett Volta leváltására hivatott, és bár a Turing köré épülõ RTX sorozat helyét is az Ampere technológiával készült modellek váltják majd, az RTX 3000-rõl egyelõre nem esett szó. Az újdonság pedig nem más, mint a GA100 mely a valaha készült legtekintélyesebb GPU mind kapacitásban, mind fizikai kiterjedésében. Az adatközpontok új generációjának meghajtására készült lapka rálicitál az elõd GV100 képességeire, így természetesen a TSMC 12nm-es node-járól a 7nm-esre költözik át, sosem látott elõrelépést produkálva. Elõször is a tranzisztorok száma 21,1 milliárdról 54,2 milliárdra gyarapodott, ráadásul ezt látványos növekedést úgy éri el, hogy a 826 mm²-res lapka mindössze 16 mm²-rel nagyobb elõdjénél. Az összehasonlításhoz érdemes megnézni, hogy az elõzõ generáció csúcsát jelentõ RTX 2080 Ti kártya 754 mm²-res lapkája 18,6 milliárd tranzisztort tartalmaz.
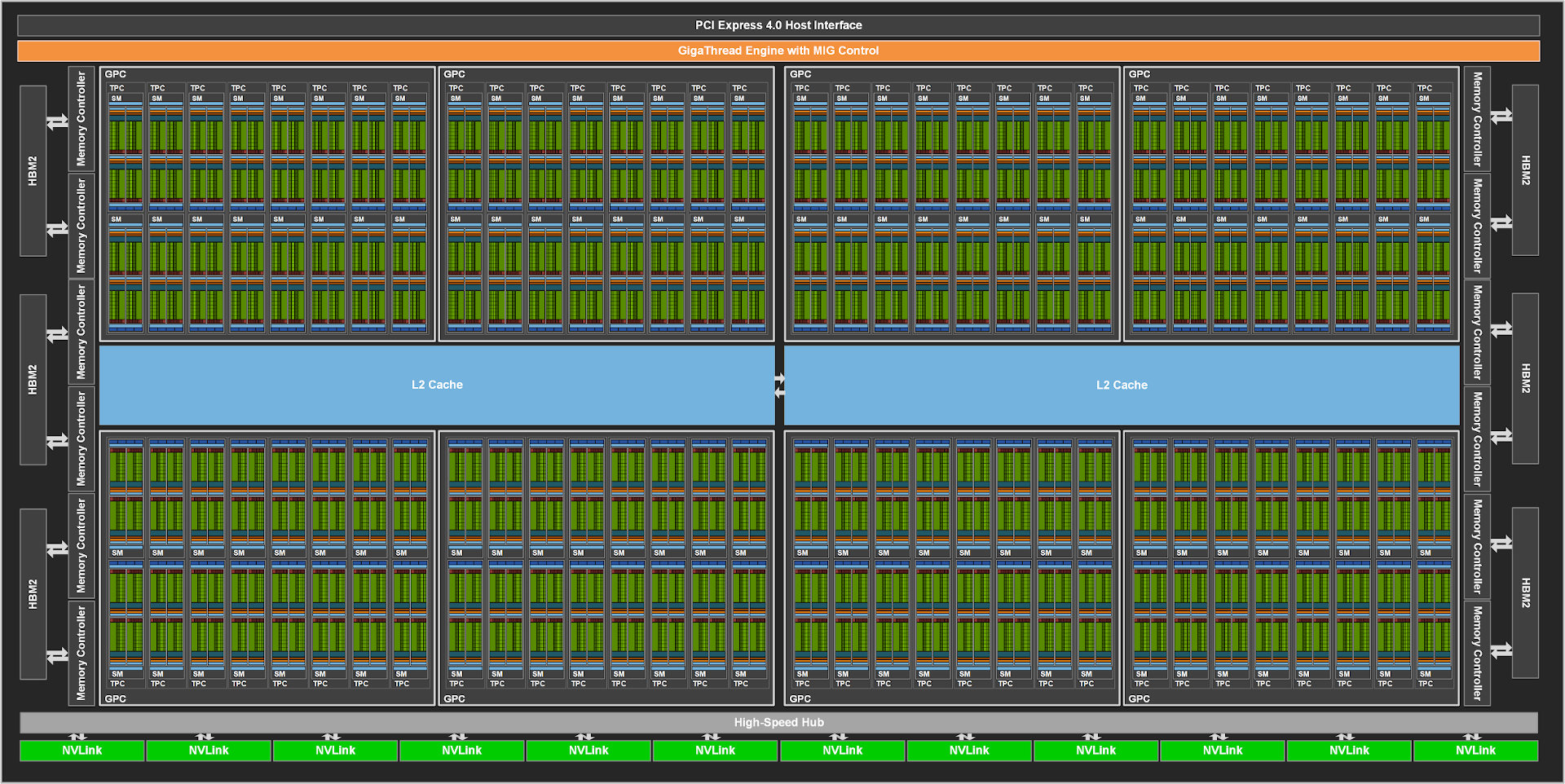
A CUDA magok száma 5120-ról 6912-re nõtt, a lebegõpontos FP32 számítási teljesítmény pedig egy izmos 4.2 TERAFLOP pluszt könyvelhet el másodpercenként. A számítási kapacitás jelentõs növekedéséhez pedig 40GB méretû HBM2 fedélzeti memória is hozzájárul, méghozzá 2.43 Ghz-es órajellel, 1.555 TB/s sávszélességgel, a GPU-val történõ kommunikációt pedig az 5120 bites adatbusz segíti. Érdekesség, hogy elvileg a hat HBM2 lapkából egy inaktív, tehát nem kizárt, hogy egy még erõsebb változatban további 1024-bit járul hozzá az amúgy is komoly összképhez.

Ahogy arra számíthattunk, az elõadásban szép nagy szelet jutott a mesterséges intelligenciára épülõ fejlesztéseknek, és a gépi tanulásnak, melyben hatalmas elõrelépést értek el, és ahogy is hangsúlyozza, az jövõ már nem a szervereké, hanem az adatközpontoké, (avagy szuperszámítógépeké, ha úgy jobban tetszik). A Tesla V100 GPU sem volt gyenge ezen a téren, de az Ampere A100 nem véletlenül kapta a "Tensor Core GPU" fedõnevet. Bár megtévesztõ lehet, hogy a V100 összesen 640 Tensor magja helyett itt csak 432 szerepel, valójában továbbfejlesztett struktúrájú magokról van szó, melyekkel nagyjából 30%-kal nõtt az összteljesítmény, így láthatóan a teljes fókusz a gépi tanulásra irányul.

Fontos újítás a Pascal architektúrával együtt bevezetett NVLINK új változata is. Az NVLink 3-as verziója, 50 Gbps sávszélességével nagyjából duplázza az NVLink 2 adatátviteli képességét, ezzel nem csak a GPU és CPU közt zajló kommunikációt gyorsítja meg jelentõs mértékben, de a több GPU-s rendszerek számára is nagy löketet ad. Az A100 amúgy 12 darab NVLinket kapott, ez a 600 Gbps pedig szintén rádupláz a V100-ra. Ehhez mérten fogyasztás is érezhetõen nõtt, de 400 watt ebben a kategóriában nem számít extrémnek. A több GPU-s rendszerekben 8 GPU alatt az NVLink látja el az összeköttetést, afölött azonban már az NVSwitch elosztóra is szükség van.

Ez tehát még nem az átlagos halandóknak szánt termékvonal, hiszen az A100 pont a grafikai munkában és a játékban nem vethetõ be. Természetesen ez nem azt jelenti, hogy az Nvidia nem készül az általános felhasználói vonalat erõsítõ termékekkel, egyszerûen csak el kell fogadnunk a tényt, hogy a legnagyobb bevétel az ipari felhasználású fejlesztésekbõl származik.
2020. 05. 15
Intel alaplap – Teljes vásárlási útmutató
Intel alaplapok – Teljes útmutató a választásához
Ha új számítógépet építesz vagy meglévő konfigurációdat fejlesztenéd, az egyik legfontosabb döntés az Intel alaplap kiválasztása. Sokan elsősorban a processzorra vagy a videokártyára koncentrálnak, pedig ezek képességeit is nagyban meghatározza, milyen alaplap kerül a gépbe. Egy rosszul megválasztott modell később kompatibilitási problémákat, korlátozott bővíthetőséget vagy felesleges kiadásokat okozhat, míg egy jól átgondolt választás hosszú évekre stabil alapot biztosít. Az sem mindegy, hogy irodai számítógépet, gamer PC-t vagy professzionális munkaállomást építesz, hiszen ugyanaz a processzor teljesen más igényeket támaszthat az alaplappal szemben. Ebben az útmutatóban végigvesszük, milyen szempontokat érdemes figyelembe venni, hogy ne csak a jelenlegi, hanem a jövőbeni igényeidnek is megfelelő Intel alaplapot válassz.
Mi az Intel alaplap, és miért fontos a megfelelő választás?
Milyen Intel platformot és chipsetet érdemes választani?
Mire figyeljünk kompatibilitás és műszaki jellemzők szempontjából?
Milyen Intel alaplapot válasszunk különböző felhasználási célokra?
Milyen hibákat érdemes elkerülni Intel alaplap vásárlásakor?
Hogyan válasszunk Intel alaplapot lépésről lépésre?
Gyakran ismételt kérdések
Összefoglaló
Mi az Intel alaplap, és miért fontos a megfelelő választás?
Első ránézésre
Ha új számítógépet építesz vagy meglévő konfigurációdat fejlesztenéd, az egyik legfontosabb döntés az Intel alaplap kiválasztása. Sokan elsősorban a processzorra vagy a videokártyára koncentrálnak, pedig ezek képességeit is nagyban meghatározza, milyen alaplap kerül a gépbe. Egy rosszul megválasztott modell később kompatibilitási problémákat, korlátozott bővíthetőséget vagy felesleges kiadásokat okozhat, míg egy jól átgondolt választás hosszú évekre stabil alapot biztosít. Az sem mindegy, hogy irodai számítógépet, gamer PC-t vagy professzionális munkaállomást építesz, hiszen ugyanaz a processzor teljesen más igényeket támaszthat az alaplappal szemben. Ebben az útmutatóban végigvesszük, milyen szempontokat érdemes figyelembe venni, hogy ne csak a jelenlegi, hanem a jövőbeni igényeidnek is megfelelő Intel alaplapot válassz.
Mi az Intel alaplap, és miért fontos a megfelelő választás?
Milyen Intel platformot és chipsetet érdemes választani?
Mire figyeljünk kompatibilitás és műszaki jellemzők szempontjából?
Milyen Intel alaplapot válasszunk különböző felhasználási célokra?
Milyen hibákat érdemes elkerülni Intel alaplap vásárlásakor?
Hogyan válasszunk Intel alaplapot lépésről lépésre?
Gyakran ismételt kérdések
Összefoglaló
Mi az Intel alaplap, és miért fontos a megfelelő választás?
Első ránézésre
AMD alaplap – Teljes vásárlási útmutató
AMD alaplapok – Teljes útmutató a választásához
Ha új számítógépet építesz, az egyik legfontosabb döntés nem a videokártya vagy a processzor kiválasztása lesz, hanem az, hogy milyen alaplapra építed a konfigurációt. Sokan hajlamosak ezt a komponenst háttérbe szorítani, pedig az alaplap határozza meg, milyen processzort, memóriát, háttértárat és bővítőkártyákat használhatsz, valamint azt is, hogy a rendszer mennyire lesz fejleszthető a következő években. Egy rosszul megválasztott alaplap később felesleges kompromisszumokat vagy akár plusz költségeket is jelenthet. Az AMD platform ráadásul több különböző foglalatot és chipsetet kínál, ezért nem mindig egyértelmű, melyik modell lesz a legjobb választás. Ebben az útmutatóban végigvesszük a legfontosabb szempontokat, hogy magabiztosan választhasd ki azt az AMD alaplapot, amely valóban illik az igényeidhez.
Mi az AMD alaplap, és miért fontos a megfelelő választás?
Milyen AMD platformot és chipsetet érdemes választani?
Mire figyeljünk kompatibilitás és műszaki jellemzők szempontjából?
Milyen AMD alaplapot válasszunk különböző felhasználási célokra?
Milyen hibákat érdemes elkerülni AMD alaplap vásárlásakor?
Hogyan válasszunk AMD alaplapot lépésről lépésre?
Gyakran ismételt kérdések
Összefoglaló
Mi az AMD alaplap, és miért fontos a megfelelő választás?
Az alaplap nem látványos alkatrész, mégis erre ép
Ha új számítógépet építesz, az egyik legfontosabb döntés nem a videokártya vagy a processzor kiválasztása lesz, hanem az, hogy milyen alaplapra építed a konfigurációt. Sokan hajlamosak ezt a komponenst háttérbe szorítani, pedig az alaplap határozza meg, milyen processzort, memóriát, háttértárat és bővítőkártyákat használhatsz, valamint azt is, hogy a rendszer mennyire lesz fejleszthető a következő években. Egy rosszul megválasztott alaplap később felesleges kompromisszumokat vagy akár plusz költségeket is jelenthet. Az AMD platform ráadásul több különböző foglalatot és chipsetet kínál, ezért nem mindig egyértelmű, melyik modell lesz a legjobb választás. Ebben az útmutatóban végigvesszük a legfontosabb szempontokat, hogy magabiztosan választhasd ki azt az AMD alaplapot, amely valóban illik az igényeidhez.
Mi az AMD alaplap, és miért fontos a megfelelő választás?
Milyen AMD platformot és chipsetet érdemes választani?
Mire figyeljünk kompatibilitás és műszaki jellemzők szempontjából?
Milyen AMD alaplapot válasszunk különböző felhasználási célokra?
Milyen hibákat érdemes elkerülni AMD alaplap vásárlásakor?
Hogyan válasszunk AMD alaplapot lépésről lépésre?
Gyakran ismételt kérdések
Összefoglaló
Mi az AMD alaplap, és miért fontos a megfelelő választás?
Az alaplap nem látványos alkatrész, mégis erre ép
Tablet gyerekeknek – Vásárlási útmutató szülőknek
Tablet gyerekeknek – Vásárlási útmutató szülőknek
Mielőtt belevágnál a vásárlásba, érdemes egy pillanatra megállni, és átgondolni, hogy valóban milyen készülékre van szüksége a gyermekednek. A “Tablet gyerekeknek” kifejezésre rengeteg találatot találsz, a kínálat pedig az olcsó belépőszintű modellektől egészen a prémium készülékekig terjed. Könnyű elveszni a specifikációk, márkák és akciók között, pedig a legjobb döntést nem feltétlenül a legismertebb gyártó vagy a legerősebb hardver jelenti. Sokkal fontosabb, hogy a tablet igazodjon a gyermek életkorához, felhasználási szokásaihoz és a család elvárásaihoz. Ebben az útmutatóban végigvesszük azokat a szempontokat, amelyek valóban számítanak, így könnyebben megtalálhatod azt a készüléket, amely hosszú távon is jó választás lehet.
Milyen szempontok alapján válasszunk tabletet gyerekeknek?
Milyen hardverre van szüksége egy gyerek tabletjének?
Android vagy iPad? Melyik rendszer éri meg jobban?
Mennyire fontos a szülői felügyelet és a biztonság?
Milyen kiegészítők érik meg egy gyerek tablet mellé?
Mennyiért érdemes tabletet venni gyerekeknek?
Hogyan válasszuk ki a megfelelő tabletet a gyermek életkora szerint?
Gyakori kérdések
Konklúzió
Milyen szempontok alapján válasszunk tabletet gyerekeknek?
A legtöbb szülő ott követi el az első hibát, hogy rögtön a márkákat kezdi összehasonlítani. Pedig
Mielőtt belevágnál a vásárlásba, érdemes egy pillanatra megállni, és átgondolni, hogy valóban milyen készülékre van szüksége a gyermekednek. A “Tablet gyerekeknek” kifejezésre rengeteg találatot találsz, a kínálat pedig az olcsó belépőszintű modellektől egészen a prémium készülékekig terjed. Könnyű elveszni a specifikációk, márkák és akciók között, pedig a legjobb döntést nem feltétlenül a legismertebb gyártó vagy a legerősebb hardver jelenti. Sokkal fontosabb, hogy a tablet igazodjon a gyermek életkorához, felhasználási szokásaihoz és a család elvárásaihoz. Ebben az útmutatóban végigvesszük azokat a szempontokat, amelyek valóban számítanak, így könnyebben megtalálhatod azt a készüléket, amely hosszú távon is jó választás lehet.
Milyen szempontok alapján válasszunk tabletet gyerekeknek?
Milyen hardverre van szüksége egy gyerek tabletjének?
Android vagy iPad? Melyik rendszer éri meg jobban?
Mennyire fontos a szülői felügyelet és a biztonság?
Milyen kiegészítők érik meg egy gyerek tablet mellé?
Mennyiért érdemes tabletet venni gyerekeknek?
Hogyan válasszuk ki a megfelelő tabletet a gyermek életkora szerint?
Gyakori kérdések
Konklúzió
Milyen szempontok alapján válasszunk tabletet gyerekeknek?
A legtöbb szülő ott követi el az első hibát, hogy rögtön a márkákat kezdi összehasonlítani. Pedig
Értékelések